
RPC Data Quality
You're getting incorrect data
Something that I’ve spent a lot of time going deep on recently is around RPC data quality. How do you know if the data you’re getting from a node is correct? Do you just trust they’re doing a good enough job? If so, you’re probably getting incorrect data.
From our data at RouteMesh, the best providers have a data correctness range of 92% to the occasional 100%. Others end up being correct only 60% of the time!
Before we get into breaking down these numbers with charts and graphs, lets talk about the two dimensions of data quality that matter.
Lag: how up-to-date is this node to the tip of the chain?
Quality: how correct is the data being returned?
The unfortunate reality is that determining either of these is a challenge without large scale infrastructure that is purpose built around these objectives. In order to convey the comprehensiveness of each, I’ll break them down so we can be on the same page.
Lag
To determine how much a node is lagging, we need to know
What is the most recent block time we’re getting from most nodes at a defined point in time?
Monitor the average block time for a chain to infer activity levels of a chain & to sanity check our data
Once we have both of these, we can call eth_getBlock:latest on an RPC node and compare the nodes against each other. These checks are done at a frequency proportional to the activity of a chain itself. A chain that has a low block production time will need more aggressive checks relative to a chain that has a high block production rate.
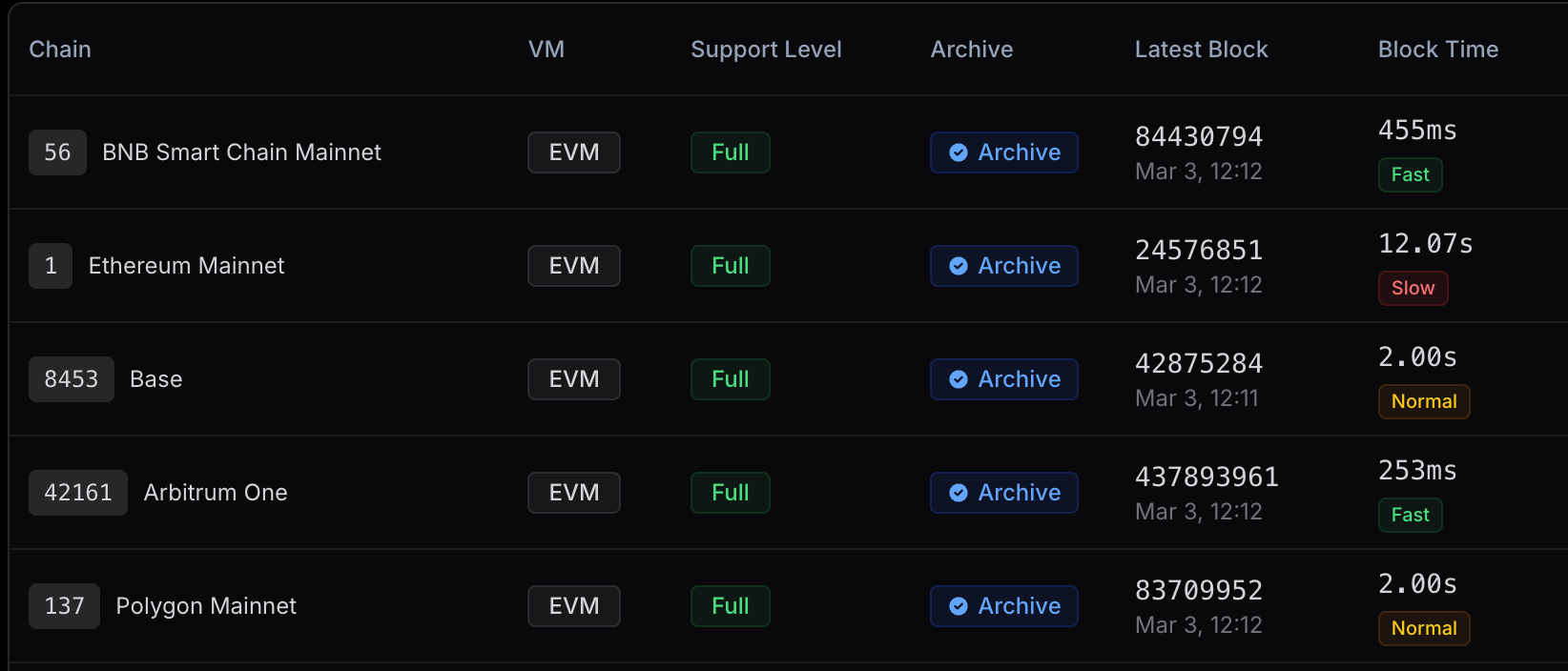
Quality
This one is more challenging and requires more engineering effort and intelligent inventory management to be economical. The simplest way to check for correctness is to make every call twice across two providers. However, not only can that be economically infeasible at scale, but it may not be correct if your two providers have a questionable track record themselves of being correct. Assuming two providers that are correct 90% of the time, you could still have incorrect data 1% of the time which can have massive consequences at scale (every 10 rows in 1000 are wrong in your database).
So how do we determine data quality, our process is as follows:
Trigger a data quality check one in every few thousand requests
Each data quality check will “replay” the request in real-time (non-blocking) across another nodes
Responses are compared across providers to determine what the majority result was (at least 3 non-null responses are required to determine finality)
Incorrect nodes are striked and depending on our configuration, are removed from the node pool alltogether
Striked nodes have to prove themselves continually across “staging” rounds to prove that they are back on track to serving correct data. This number is disproportionately higher than the strike count. Easy to be taken out, hard to get back in. While nodes are staged, they are not serving real data but rather being tested.
The pool of correct nodes shrinks over time to the most correct set..
Here’s a little animation that illustrates this process visually.

In the rest of this article, we’ll be referring to these checks are “replay” checks as we replay the request sent in the first place.
Note: we use hash-based consensus checks so there are minor inaccuracies when doing comparisons. We’re constantly in the process of correcting although these will not impact in a substantial way.
The Data
Now that we’re on the same page about the methodology used and how it is determined, it’s time to spill some data. For this article I’m going to refer to the top three RPC providers at the time of writing (Alchemy, Quicknode and Chainstack). Black boxes indicate that we don’t have enough checks with that provider on that day to draw any reasonable conclusions. These checks are averaged out across all three major regions (canada-east, frankfurt, singapore)
Alchemy
This the data of how “in-sync” Alchemy’s entire node fleet was for the past 30 days. Their nodes are mainly in-sync except for the odd node here and there that has issue. Nothing too much to learn here although this data changes month-to-month quite a lot.
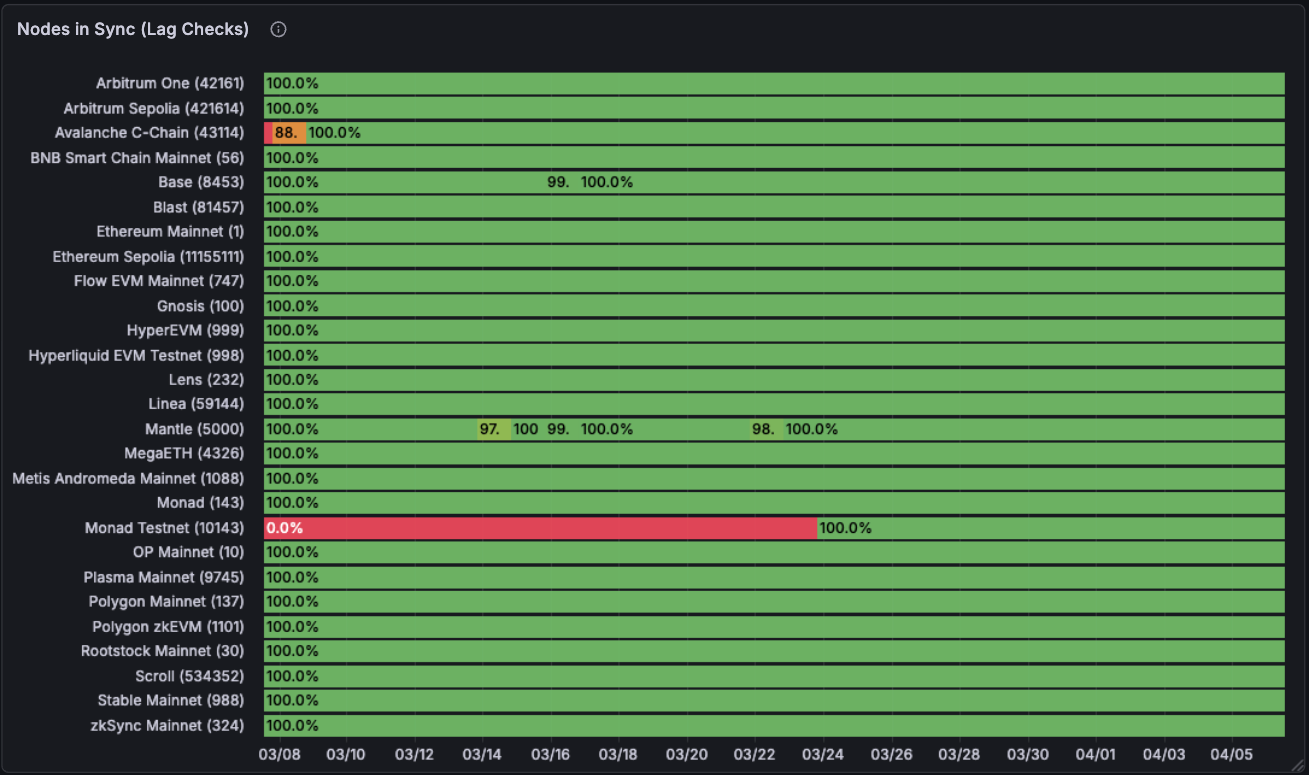
Now, moving on to node correctness. This one is a lot less pretty. Some chains on certain days report very incorrect data. Ethereum mainnet had some big hiccups in mid march. Chains like HyperEVM are right 96-98% of the time which isn’t great if you are building data pipelines on top. The black gaps are when we don’t have any data for that time-frame.
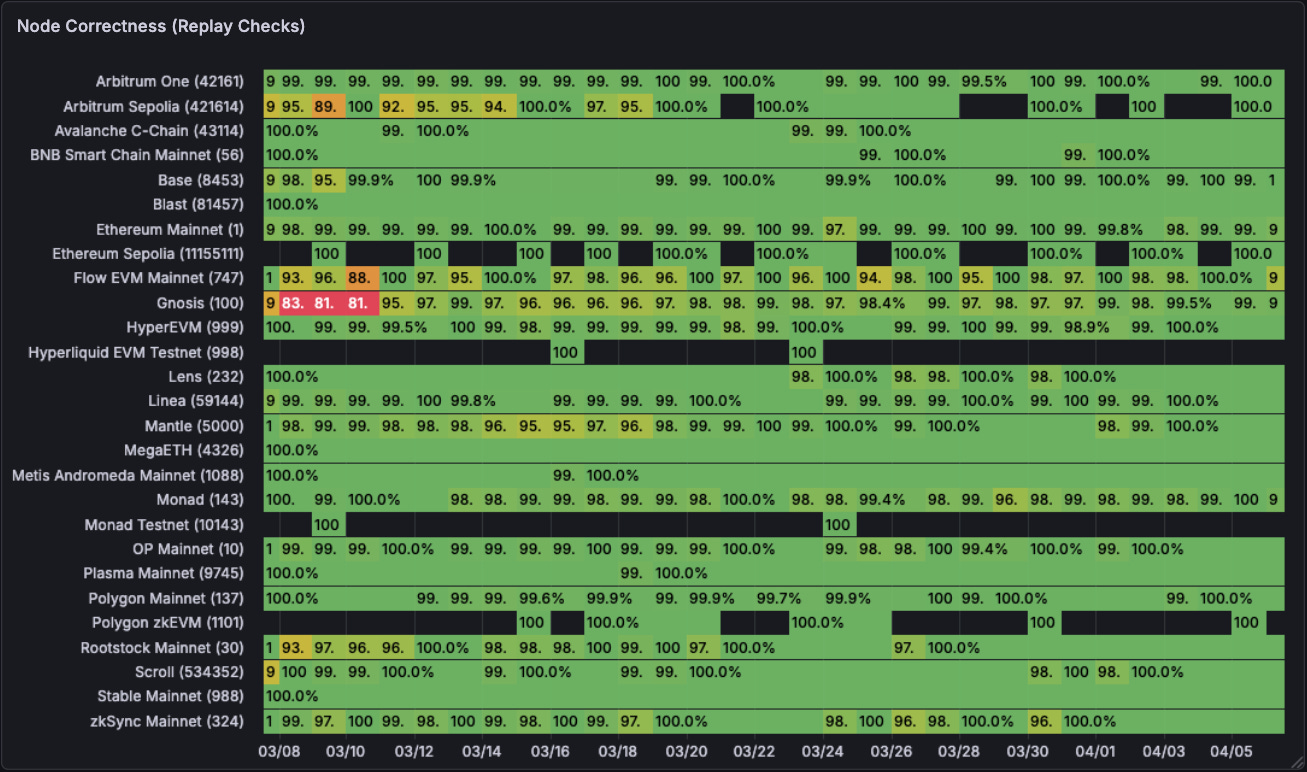
Quicknode
Unlike Alchemy, Quicknode’s fleet of nodes is usually more out-of-sync with the tip of the chain. Maybe they don’t care about certain chains or they’re in the process of discontinuing them but there are indeed some not-so-pretty results for chains here relative to Alchemy.
Okay coming up next is data quality for Quicknode. While not as bad as Alchemy, still concerning for what should be an enterprise grade data provider in the space. Arbitrum nodes have major issues, same with Ethereum and Polygon. It feels like Quicknode is correct most of the time but wrong majorly at certain times. Alchemy is kind of correct most of the time.
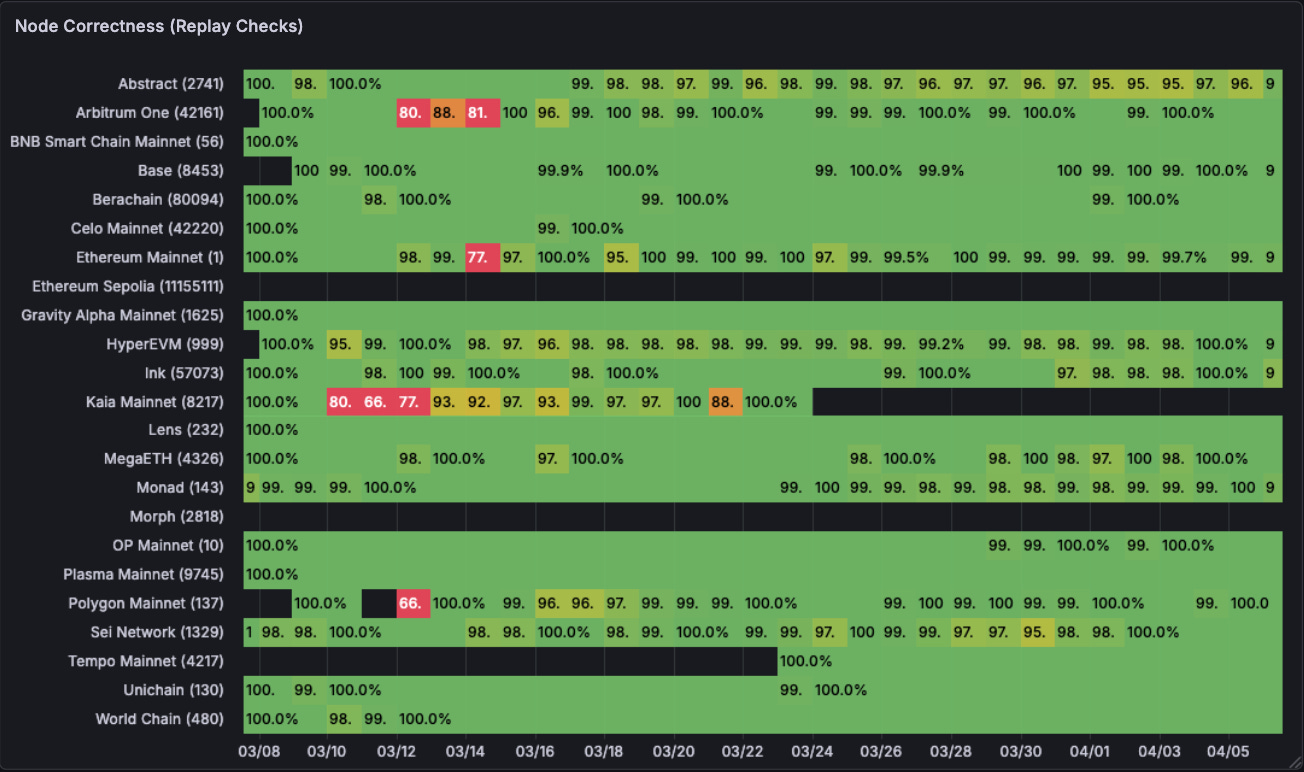
Chainstack
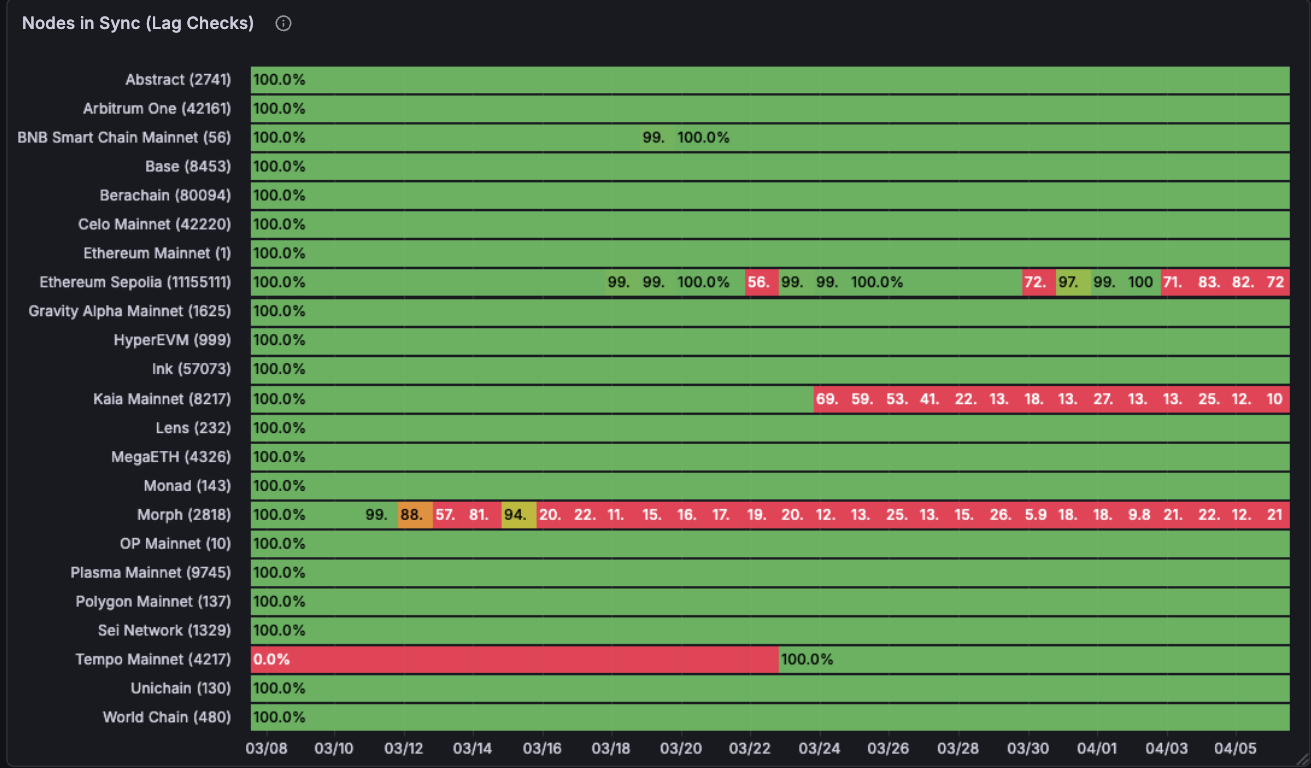
Performance for lag checks is good holistically although some chains are poorly maintained and lag massively, consistently. Mantle and Sonic here. They also have brief drops in time for chains like Polygon mainnet which are of concern.
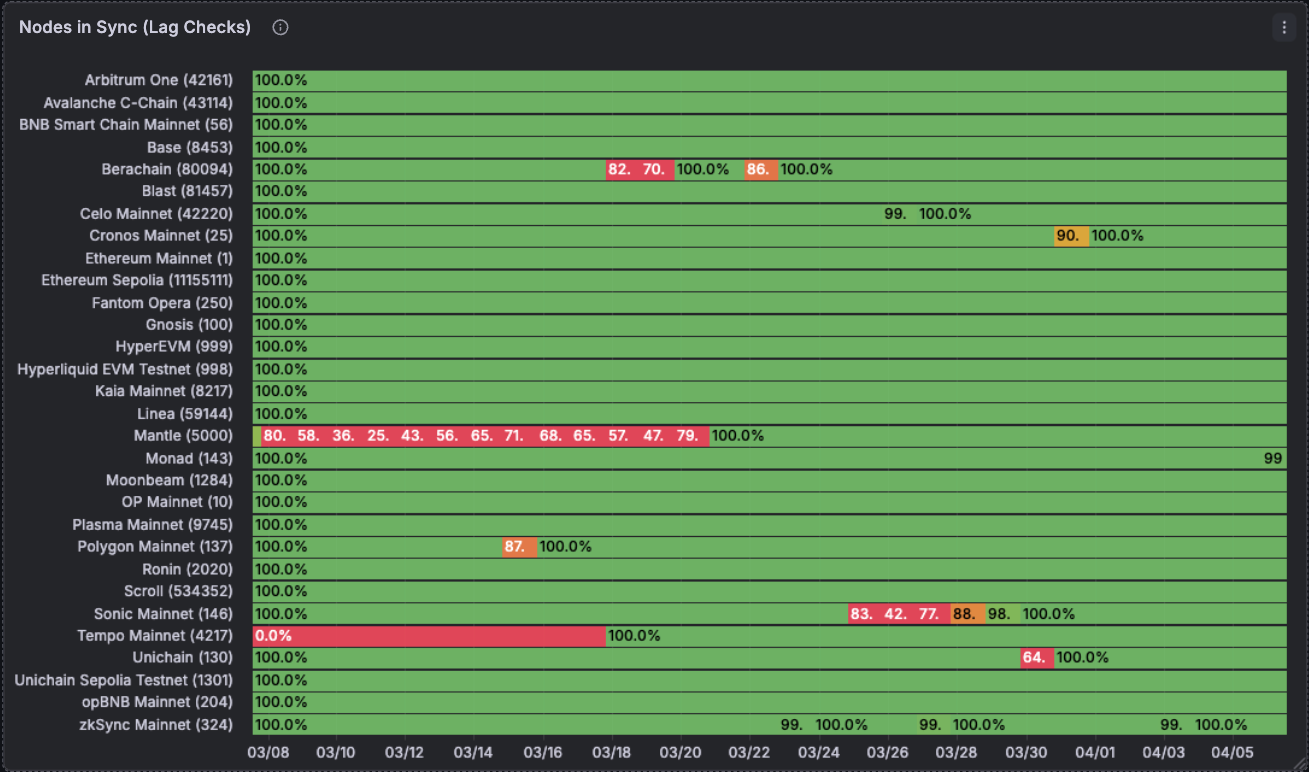
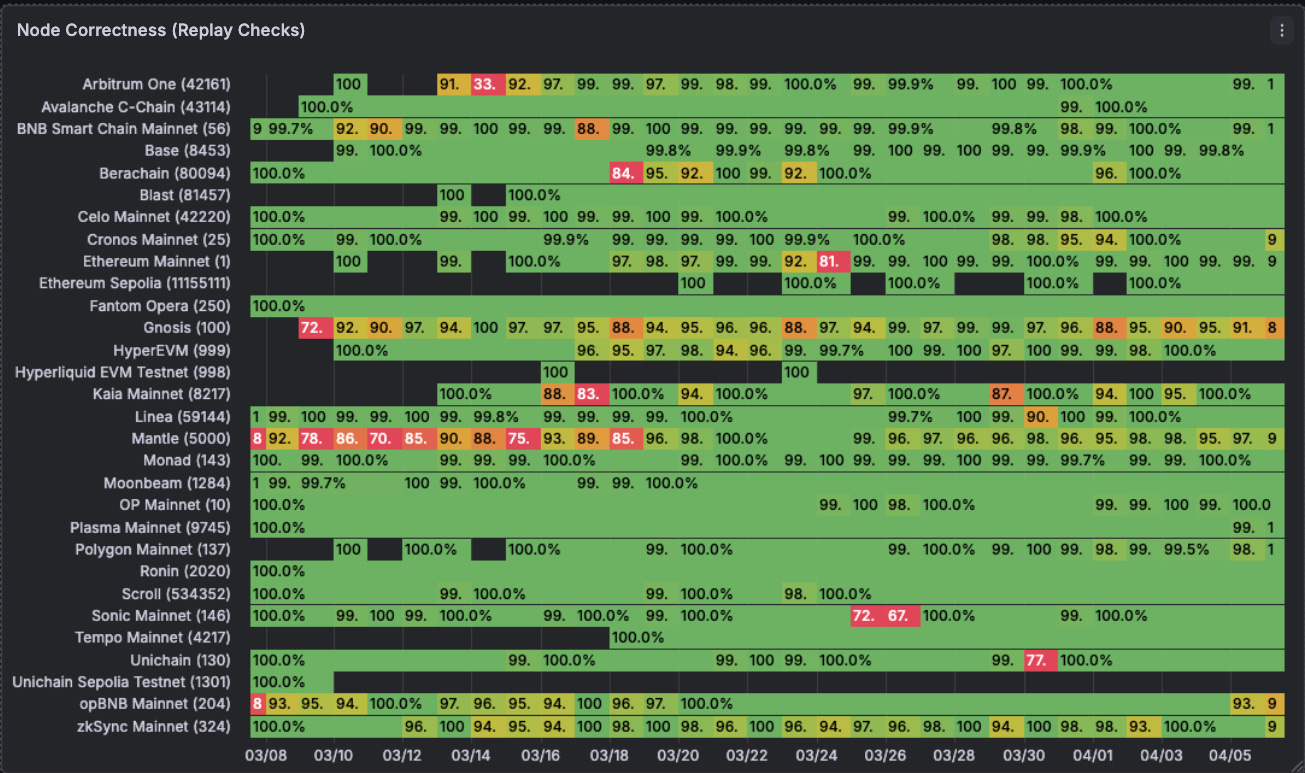
On the replay check side, while Chainstack’s nodes have a lot more of a greater challenge with being correct. Our data consistently shows that they their nodes can have below acceptable ranges of correctness. That being said, with RouteMesh’s technology we can separate the good from the bad in this picture and still utilise the nodes that are good.
Concerns
My biggest concern with all of this is the fact that most of the industry is paying money for incorrect data that is used further in downstream datasets. Data indexing companies are usually aware of this and have some form of checking/redundancy in place but that is unattainable for smaller companies who are hoping to get correct, up-to-date data from their RPC providers.
Open source data should be accessible to all and most importantly, correct.
Given most of the industry relies on static pricing models, they are not being compensated or neither have the incentive to fix the issues on these chains since doing so will not lead to incremental revenue unless the customer is as sophisticated as RouteMesh running intense data filtering and monitoring pipelines on them.
At RouteMesh, we do all of this work so that our customers are getting correct, up-to-date data from node providers without having to worry about this entire hassle. We also pay certain more providers more if they genuinely do a good job of doing the thing they were meant to do: run nodes.
Closing
All the data here is data used live in our production systems and routing algorithms serving billions of requests, if there were any issues with it our customers end up calling us out very quickly for it. We have no vested interest in promoting or demoting any single providers. Our job is to deliver the best RPC service so our customers can focus on getting the data they need for their products.
We have all of this data live at https://routeme.sh/providers for you to checkout yourself. I believe this is one of the highest value problems to solve as RPCs and data are:
One of the most primitive building blocks of this industry
One of the least transparent parts of this industry
Global latencies, pricing, chain support, rate limits are a whole new can of worms I still have not discussed but will be writing at lengths about.
Our data quality checking system (sentinel) is constantly being improved to adapt to provider inconsistencies, chains, methods etc. We do this work so our customers don’t have to!
Really interesting breakdown of RPC data quality, especially the replay + majority approach.
One thing we’ve been digging into is how to measure state correctness beyond node agreement. Majority voting works well, but can still break when multiple nodes return the same incorrect result.
We’re working on a complementary layer around verifiable execution (WASM + zk) and consistency scoring, which could potentially reduce replay overhead and improve node selection.
Curious if you’ve thought about confidence in state as a separate primitive from node-level trust.